Künstliche Intelligenz im Archiv – den Umgang mit einem komplexen Thema finden
Künstliche Intelligenz (KI) lässt sich sinnbildlich als „Drache“ beschreiben: ein mächtiges und vielschichtiges Thema, das zunächst unübersichtlich erscheint. Die Tagung bei der Deutschen Telekom AG in Bonn verdeutlichte, wie hilfreich es ist, KI zunächst aus unterschiedlichen Perspektiven zu betrachten, um anschließend gezielt Einsatzmöglichkeiten zu identifizieren.
Der erste Teil der Veranstaltung bot Einblicke in technische und rechtliche Grundlagen sowie in bereits verfügbare KI-Anwendungen. Neben dem praktischen Nutzen wurden auch Grenzen und Herausforderungen thematisiert, etwa hinsichtlich Datenqualität, Transparenz und rechtlicher Rahmenbedingungen.
Im zweiten Teil wurden Best-Practice-Beispiele aus Unternehmensarchiven vorgestellt, die KI bereits in konkreten Projekten einsetzen. Die vorgestellten Erfahrungen machten sowohl Potenziale als auch Hemmnisse deutlich.
Fazit der Tagung: Der Einsatz von KI im Archivwesen bietet Chancen, erfordert jedoch neben Offenheit und Experimentierbereitschaft auch kritische Reflexion. Der entscheidende Faktor bleibt der Mensch, der Ziele definiert, Systeme bewertet und Verantwortung übernimmt.

Was ist Künstliche Intelligenz – und wo steht sie heute?
Einen grundlegenden Überblick über das Thema Künstliche Intelligenz gab Arno Selhorst, KI-Experte bei der Deutschen Telekom. Er skizzierte sowohl die Entwicklungslinien der KI als auch den aktuellen Stand der Technik und ordnete diese für den praktischen Einsatz in Organisationen ein.
Ein Meilenstein war der Launch von ChatGPT im Jahr 2022. Bereits 2023 folgte mit Systemen wie GPT‑4 oder Google Gemini der nächste Entwicklungsschritt, bei dem Text‑ und Bildverarbeitung kombiniert wurden. Für 2025 wird der verstärkte Einsatz sogenannter agentischer KI-Systeme erwartet, während ab 2026 erste dedizierte KI-Hardware zunehmend an Bedeutung gewinnen dürfte.
Aus Sicht von Selhorst bestehen die zentralen Herausforderungen im Umgang mit KI auf mehreren Ebenen. Technisch entstehen nahezu täglich neue Anwendungen, die bewertet und auf ihre Nutzbarkeit überprüft werden müssen. Gleichzeitig sei es ein Irrtum, davon auszugehen, KI könne „alles“ übernehmen oder jeder könne ohne Fachkenntnis KI-Systeme entwickeln. Organisatorisch besteht die Gefahr paralleler Entwicklungen, wenn fehlende Abstimmung dazu führt, dass identische Lösungen mehrfach aufgebaut werden. Hinzu kommen rechtliche Fragen: Was ist zulässig, und wie lassen sich KI-Anwendungen regelkonform in bestehende Strukturen integrieren?
Für Archive formulierte Selhorst einen konkreten Praxistipp: Vor dem Einsatz eines KI-Tools sollte geprüft werden, ob und wie eine Anbindung an die bestehenden Archivsysteme möglich ist. Schnittstellen und Integration sind entscheidend für eine nachhaltige Nutzung.
Seine übergeordnete Empfehlung fasste er prägnant zusammen:
„Stay calm & keep prompting.“
Das zentrale Learning bleibt dabei der Faktor Mensch – als Voraussetzung für Bewertung, Steuerung und verantwortungsvollen Einsatz von KI.
Weiterführende Einblicke bietet ein Podcast mit Arno Selhorst: KI Pioniere - Wie Arno Selhorst eine Bewegung im Konzern entfesselte

Rechtliche Rahmenbedingungen für den Einsatz von KI im Archiv
Die rechtlichen Aspekte der KI-Nutzung standen im Mittelpunkt des Vortrags von Prof. Dr. Thomas Henne von der Archivschule Marburg, einem ausgewiesenen Experten für Archivrecht. Er gab einen systematischen Überblick über die relevanten juristischen Fragestellungen, insbesondere im Hinblick auf Datenschutz, Urheberrecht und neue europäische Regulierungen.
Zentrale Rolle spielt der Datenschutz nach der DSGVO. Alle archivischen Fachaufgaben gelten grundsätzlich als „Weiterverarbeitung“ im Sinne der DSGVO und sind damit zunächst verboten, sofern keine entsprechende Erlaubnis greift. Eine Weiterverarbeitung durch KI liegt nach Henne nicht vor, wenn KI ausschließlich zur technischen Vorbereitung archivischer Fachaufgaben eingesetzt wird. Anders verhält es sich, wenn Daten mithilfe von KI für neue Zwecke ausgewertet werden – hier ist eine datenschutzrechtliche Zulässigkeit erforderlich. Als praktische Maßnahme empfahl Henne unter anderem, in Mitarbeiterverträgen eine Einwilligung zur Übernahme von Unterlagen in das Unternehmensarchiv vorzusehen.
Auch urheberrechtliche Fragen sind beim KI-Einsatz relevant. Während für rein technische Vorbereitungsschritte keine urheberrechtliche Erlaubnis nötig ist, gilt dies nicht, wenn KI Inhalte auswertet, verändert oder neu kombiniert. In solchen Fällen sind entsprechende Erlaubnisklauseln erforderlich, begleitet von einem strukturierten Risikomanagement.
Der europäische Rechtsrahmen bietet insgesamt ein hohes Maß an Absicherung durch Datenschutzgesetze und Aufsichtsbehörden. Ab August treten zudem spezielle Regelungen zur KI in Kraft, die KI-Anwendungen in vier Risikoklassen einteilen. Für niedrigere Risikostufen sind Transparenz- und Kennzeichnungspflichten vorgesehen, bei höheren Risikostufen kommen zusätzliche Anforderungen bis hin zu Qualifizierungs- und Schulungspflichten für das eingesetzte Personal hinzu.
Als zentrale Leitlinie für Archive formulierte Henne das Gebot der Transparenz und Nachvollziehbarkeit. Entscheidungsprozesse müssen dokumentierbar bleiben, etwa durch die Speicherung von Prompts. KI-generierte Erschließungsdaten sind als solche zu kennzeichnen, und die Verantwortlichkeit für den KI-Einsatz muss klar benannt sein. Die Einhaltung dieser Prinzipien trägt wesentlich zur Akzeptanz insbesondere von Wirtschaftsarchiven bei.
Zur Vertiefung verwies Henne auf das Konsortium NFDI4Memory im Rahmen der Nationalen Forschungsdateninfrastruktur (NFDI). Das Netzwerk vereint rund 80 Einrichtungen – darunter Archive, Bibliotheken, Museen und Forschungseinrichtungen – und fördert die Entwicklung und Integration digitaler Methoden und Infrastrukturen für die historische Forschung. Weitere Informationen dazu gibt es hier: 4Memory / Nationale Forschungsdaten Infrastruktur (NFDI)
Werkzeuge und Dienstleistungen: Aktuelle Ansätze für Unternehmen und Archive
Einen praxisnahen Einblick in den unternehmerischen Einsatz von KI gab Nino Flück (Zoi). Anhand einer Demonstration zeigte er, wie sich historische Daten aus einem Unternehmensarchiv mithilfe von KI für eine vollständige Produktkampagne nutzen lassen – von der Identifikation relevanter Archivunterlagen über die strukturierte Prompt-Erstellung bis hin zur Generierung von Werbetexten, Videos, Audiozusammenfassungen oder Podcasts. Entscheidend ist dabei die klare fachliche Steuerung: KI arbeitet nur so gut wie die Vorgaben, die sie erhält. Das Learning aus dieser Perspektive: Archivbestände können bei entsprechender Aufbereitung weit über Dokumentation hinaus strategischen Mehrwert entfalten, wenn Ziele, Kontexte und Qualitätskriterien klar definiert sind.
Aus Sicht von Unternehmensarchiven und historischer Forschung wurden weitergehende Ansätze vorgestellt, die über reine Datenaufbereitung hinausgehen. Ein gemeinsames Projekt von Dr. Matthias Georgi, Neumann & Kamp, und Prof. Tim Bruysten, ESSCA, zielt darauf ab, Archivbestände mithilfe von KI systematisch zu analysieren, um unternehmerische Erfolgsmuster sichtbar zu machen. Ergänzend berichtete Markus Stauffiger, Archipanion, aus der Praxis verschiedener Archive über KI-gestützte Erschließung, Strukturierung und Suche – etwa bei Massendaten, Gerichtsurteilen, Karteikarten oder Sitzungsprotokollen. Die Erfahrungen zeigen: KI kann Erschließungsrückstände abbauen und Datennutzung deutlich erleichtern, bleibt aber ein Werkzeug mit Fehleranfälligkeit und Grenzen, insbesondere bei Handschriften. Zentrales Learning über alle Beispiele hinweg: KI ersetzt keine archivische Expertise, sondern verstärkt sie – Lernbereitschaft, Qualitätskontrolle und fachliche Verantwortung bleiben entscheidend.

KI als Werkzeug für externe Anforderungen: Nutzeranfragen im Fokus
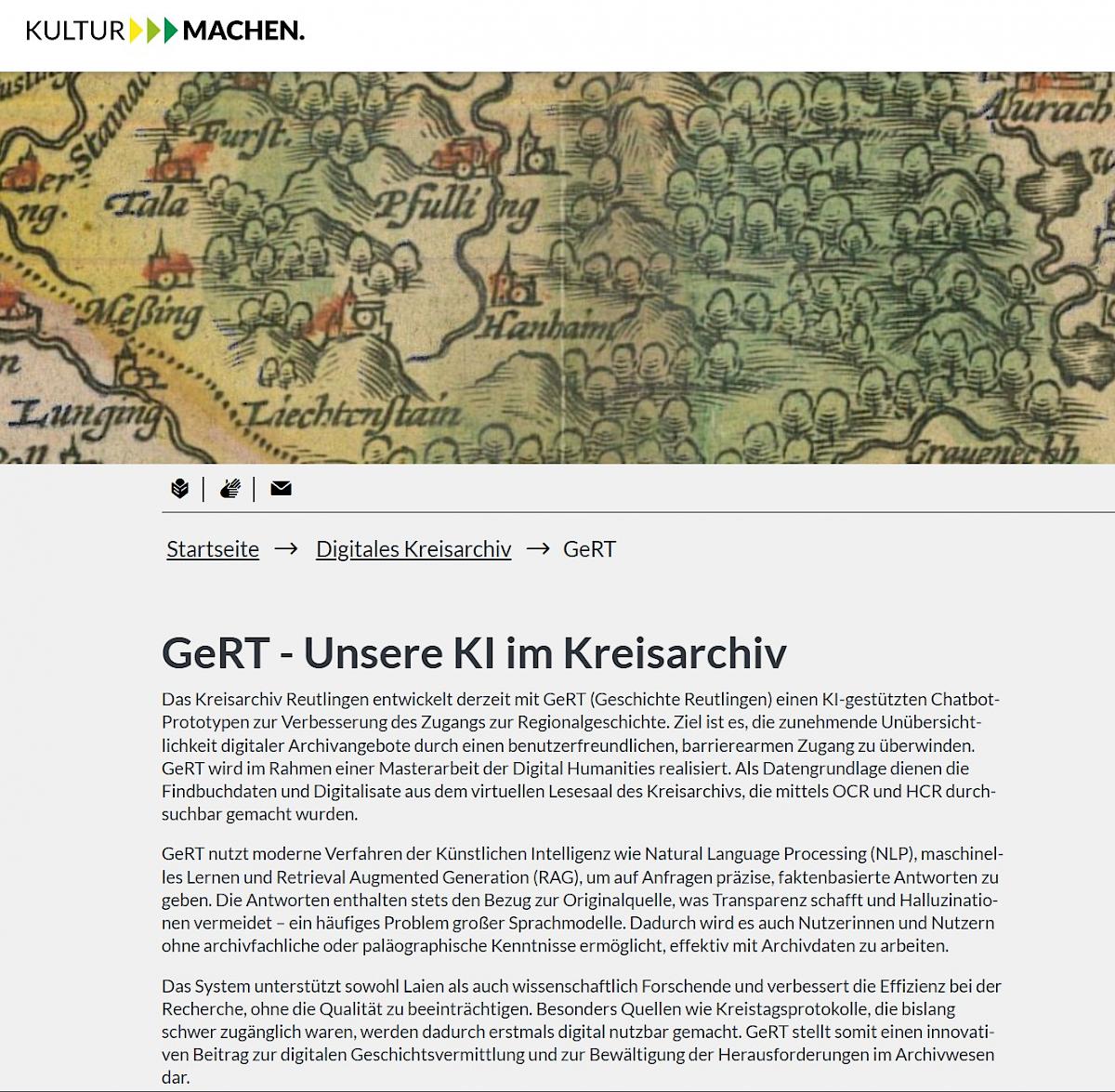
Wie Künstliche Intelligenz zur Unterstützung externer Nutzeranfragen eingesetzt werden kann, zeigten Dr. Marco Birn, Kreisarchiv Reutlingen, und Melanie Weber, Universität Stuttgart, am Beispiel des Projekts GeRT. Ziel des Projekts ist es, einen niedrigschwelligen Zugang zu Informationen aus Archivbeständen zu ermöglichen und insbesondere ersten Orientierungsbedarf von Nutzenden zu bedienen.
GeRT entstand im Rahmen einer Kooperation zwischen Archiv und Hochschule und geht auf eine Masterarbeit im Bereich Digital Humanities zurück. Das System ermöglicht es Archivnutzenden und Forschenden, Fragen zur Geschichte Reutlingens oder zu Archivbeständen zu stellen. Als Antwort liefert die KI neben einer zusammenfassenden Auskunft auch relevante Textstellen aus den zugrunde liegenden Archivdokumenten. Dabei behält das Archiv die Kontrolle über die Inhalte: Es entscheidet selbst, welche Dokumente in das System eingespeist werden und somit für die Auswertung zur Verfügung stehen.
In der Praxis hat sich gezeigt, dass insbesondere konkrete, klar formulierte Fragen gut beantwortet werden können. GeRT eignet sich damit als Instrument zur Erstorientierung und als ergänzendes Serviceangebot. Für vertiefende Recherchen und belastbare Auskünfte bleibt jedoch die direkte Kontaktaufnahme mit dem Archiv unerlässlich. Zu den Grenzen des Systems zählen die bislang eingeschränkte Erkennung handschriftlicher Quellen, eine nicht immer vollständig korrekte Antwortgenerierung sowie der hohe Speicherbedarf.
Das Projekt verdeutlicht, wie KI gezielt eingesetzt werden kann, um externe Anforderungen zu unterstützen, ohne archivische Kernaufgaben oder die fachliche Verantwortung zu ersetzen. Weitere Informationen zum Projekt finden sich unter: GeRT | Kulturplattform Reutlingen
KI als Werkzeug für Transkription
Philipp Gottschalk, Evonik Industries, berichtete über den Einsatz von KI zur Transkription handschriftlicher Karteikarten. Ziel war es, historische Bestände zu digitalisieren und inhaltlich nutzbar zu machen. Nach der Digitalisierung wurden die Scans mithilfe einer KI (Gemini) transkribiert und anschließend manuell durch das Team überarbeitet.
Die Ergebnisse zeigten eine hohe Abhängigkeit von der Qualität der Handschrift. Während einige Transkriptionen gut nutzbar waren, fielen andere unzureichend aus. Zudem neigt KI zu sogenannten Halluzinationen, etwa durch eigenständige Gliederungen, Zusammenfassungen oder kreative Ergänzungen. Eine fachliche Kontrolle und Nachbearbeitung erwies sich daher als unverzichtbar. Insgesamt wurde der Einsatz dennoch positiv bewertet: Die KI konnte Arbeitszeit einsparen, da Korrekturen in der Regel weniger aufwendig sind als vollständige Neu-Transkriptionen, auch wenn die Ergebnisse nicht konsistent waren.

KI als Werkzeug für Erschließung
Zwei Praxisbeispiele zeigten, wie KI zur Erschließung sehr unterschiedlicher Medientypen eingesetzt werden kann. Markus Holmer, ERGO Group, stellte ein Projekt zur Erschließung eines umfangreichen Mikrofilmbestands vor: Rund 7.000 Mikrofilme mit insgesamt etwa 25 Millionen Seiten, deren Inhalte weitgehend unbekannt waren. Ziel war die Erstellung eines digitalen Findbuchs, um den Bestand für historische Forschung überhaupt erst zugänglich zu machen. Nach der Digitalisierung wurden die Daten durch KI ausgewertet. Das Ergebnis lieferte eine brauchbare inhaltliche Übersicht, auch wenn Fehler enthalten waren. Gleichzeitig wurde deutlich, dass der Aufwand hoch ist – finanziell, zeitlich und organisatorisch – und mit erheblichen Risiken verbunden bleibt, etwa im Hinblick auf IT‑Schnittstellen, externe Anbieter und den unklaren Nutzen im Verhältnis zum Einsatz.
Ein kontrastierendes Beispiel präsentierte Frank Hebestreit, Bayerischer Rundfunk, mit dem System GAMS, das zur Erschließung von Videobeiträgen eingesetzt wird. Ziel ist es, audiovisuelle Inhalte gezielt für Wiederverwendungen nutzbar zu machen. Auf Basis von KI (u. a. Google Gemini) werden aus Videos automatisch Metadaten wie Szenenbeschreibungen, Schlagworte und Zusammenfassungen generiert. Die Ergebnisse können in einer App überprüft und nachbearbeitet werden. Auch hier ist eine fachliche Kontrolle erforderlich, dennoch führt der Einsatz zu einer deutlichen Zeitersparnis gegenüber einer vollständig manuellen Erschließung. Beide Beispiele zeigen: KI kann Erschließungsprozesse erheblich unterstützen, ersetzt aber weder Bewertung noch Verantwortung der Archive.


KI als Werkzeug für historische Kommunikation
Thore Grimm, Bayer AG, stellte den Einsatz von KI zur Erstellung historischer Übersichten für die interne Kommunikation vor. Ziel ist es, mithilfe von KI Texte zur Unternehmensgeschichte für Veröffentlichungen im Intranet zu generieren. Dazu wird die KI gezielt mit Informationen, Dokumenten und Bildmaterial aus dem Archiv „gefüttert“. Die bisherigen Ergebnisse befinden sich noch in der Erprobungsphase: Die generierten Texte erwiesen sich als inhaltlich nicht ausreichend sachlich und benötigen deutliche fachliche Nachbearbeitung. Gleichwohl wurde der Ansatz positiv bewertet, da der Umgang mit KI – insbesondere das gezielte Prompten – nur durch praktische Anwendung erlernt werden kann.
Ein weiterer Diskussionspunkt betraf den Umgang mit historischem Material, das von Kommunikationsabteilungen mithilfe von KI für Kampagnen bearbeitet und dabei visuell oder inhaltlich verändert wird. Grimm plädierte dafür, dass Archive selbst aktiv mit KI arbeiten sollten, um fachlich mitreden und ihre Perspektive frühzeitig in unternehmensinterne Prozesse einbringen zu können.

Diskussion
In der abschließenden Diskussion wurden als zentrale Hindernisse für den KI-Einsatz im Archiv vor allem Fragen der Daten- und Ergebnisqualität, der Erkennung (insbesondere bei historischen Materialien), der Finanzierung, der organisatorischen Einbindung sowie des Verhältnisses von Aufwand und Nutzen benannt. Kontrovers diskutiert wurde zudem der Umgang mit Veränderungen historischer Dokumente durch KI: Zwischen berechtigter Sorge vor Geschichtsverfälschung und pragmatischer Nutzung für Kommunikationszwecke bleibt für Archive die Herausforderung bestehen, eine fachlich fundierte und klar kommunizierte Haltung zu entwickeln.


KI im Archiv - Do's & Don'ts
✅ Do
- Recht früh klären: Datenschutz, Datensicherheit und rechtliche Zulässigkeit von Beginn an mitdenken
- Klein anfangen: Einen konkreten Anwendungsfall identifizieren („erster Drache“)
- Selbst ausprobieren: KI aktiv nutzen, testen und Erfahrungen sammeln
- Vergleichen: Tools und Ansätze systematisch gegenüberstellen
- Neugier fördern: Offenheit für neue Methoden bewusst kultivieren
- Verbündete einbinden: IT, Datenschutz und Rechtsabteilung frühzeitig beteiligen
- Verantwortung behalten: Fachliche Steuerung und Kontrolle sicherstellen
❌ Don’t
- Technik überschätzen: KI nicht als Allheilmittel betrachten
- Recht ignorieren: Nutzung ohne rechtliche Prüfung riskieren
- Abschotten: Insellösungen ohne organisationale Abstimmung entwickeln
- Stillstand durch Skepsis: Misstrauen nicht zum Handlungshemmnis werden lassen
- Unklar bleiben: Ohne definiertes Ziel oder Nutzen experimentieren
- Organisation unterschätzen: Herausforderungen nicht auf Technik reduzieren
Hinweis: Der Beitrag wurde mit Unterstützung durch KI erstellt.
Bilder: © Deutsche Telekom AG